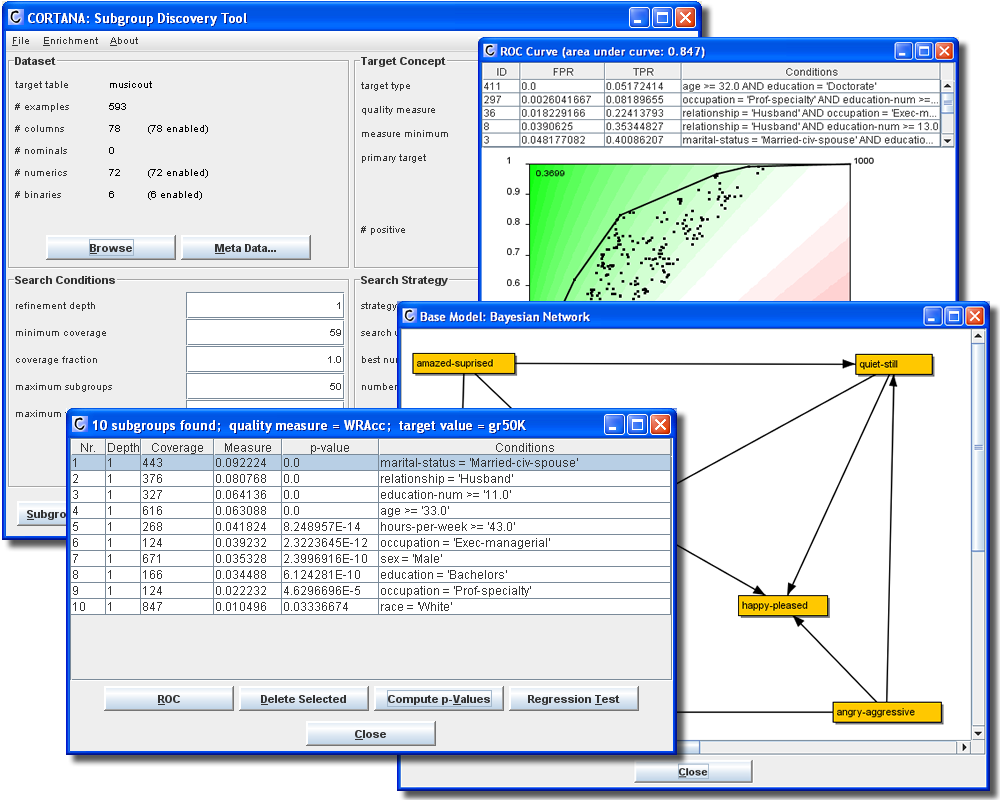
Cortana is a Data Mining tool for discovering local patterns in data. Cortana features a generic Subgroup Discovery algorithm that can be configured in many ways, in order to implement various forms of local pattern discovery. The tool can deal with a range of data types, both for the input attributes as well as the target attributes, including nominal, numeric and binary. A unique feature of Cortana is its ability to deal with a range of Subgroup Discovery settings, determined by the type and number of target attributes. Where regular SD algorithms only consider a single target attribute, nominal or sometimes numeric, Cortana is able to deal with targets consisting of multiple attributes, in a setting called Exceptional Model Mining.
Implemented in Java, so works on all major platforms, including Windows, Linux and Mac OS.
Works on propositional (tabular) data from flat files, .TXT or .ARFF.
Includes Exceptional Model Mining settings.
Statistical validation of mining results.
Graphical presentation of results, such as ROC curves, scatter plots, and exceptional models.
Additional bioinformatics module for literature-based gene set enrichment (see bioinformatics below).
Free binary version and open-source access.
Download Cortana
Binary: For obtaining a binary that will run on any modern computer, download the JAR file here.
Sources: Java sources of Cortana can be downloaded here.
Knime plug-in: A Cortana plug-in for Knime can be found here.
Bioinformatics binary: A more complete bioinformatics package can be downloaded here.
Background material: Scientific papers featuring Cortana, and a list of contributors can be found here.
Bioinformatics Module
Cortana can be used as a so-called enrichment-tool in the context of bioinformatics (pdf). When analysing, for example, gene expression data, it is fairly easy to rank genes by differential expression. A bigger challenge is to summarize this ranking of genes, essentially a list of details about individual genes, into higher-level concepts, which can lead to an understanding of the biological mechanisms at play in the data under consideration. This task of enrichment of a gene ranking can be performed using Cortana, after the necessary sources of domain knowledge have been loaded in the tool. After loading a gene ranking, one or more domain files can be loaded, which provide a large collection of background information. The enriched gene ranking can then be analysed using the regular Subgroup Discovery facilities of Cortana. The domain files that Cortana uses are based on an extensive text mining effort, and are produced by the Biosemantics group. Domain files for the desired domain(s) can be downloaded here.